Data Transformations
Bhattacharya analysis and the Hoffmann method assume that results from healthy individuals follow a Gaussian distribution. It is still possible to use Bhattacharya analysis or the Hoffmann method for analytes with non-Gaussian distributions, but a transformation must first be applied to the data.
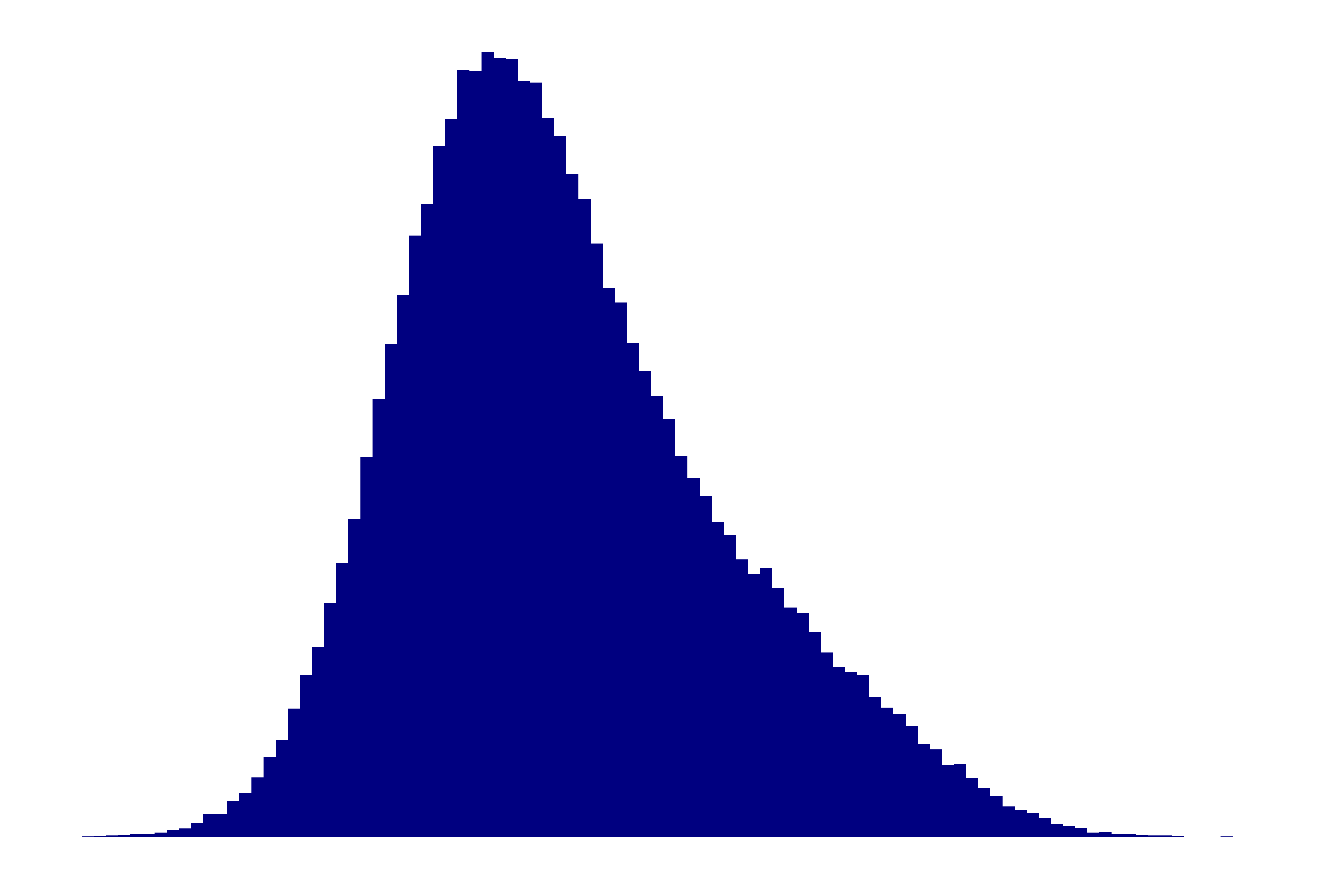 |
|---|
| Figure 1. Histogram of a simulated data set with a positive (right-sided) skew. |
It is common for mixed data sets to show skewing (Figure 1). When this is the case, the first thing to consider is its cause. If it is because the distribution of results in health is skewed then a data transformation is appropriate. However, there may be other causes of skewing for which it is inappropriate to transform the data, e.g. skewing from the presence of patients with disease, or from the presence of overlapping Gaussian distributions (as might occur with different age-groups; Figure 2). In the latter case, data should be partitioned rather than transformed.
It is helpful to get information about the expected distribution from reference intervals studies in which the participants were known to be healthy. An alternative is to try to find a sub-group in your data that is likely to be healthy - e.g. requests from ‘wellness’ clinics. It is also good practice to examine the data for any subgroups that should be partitioned.
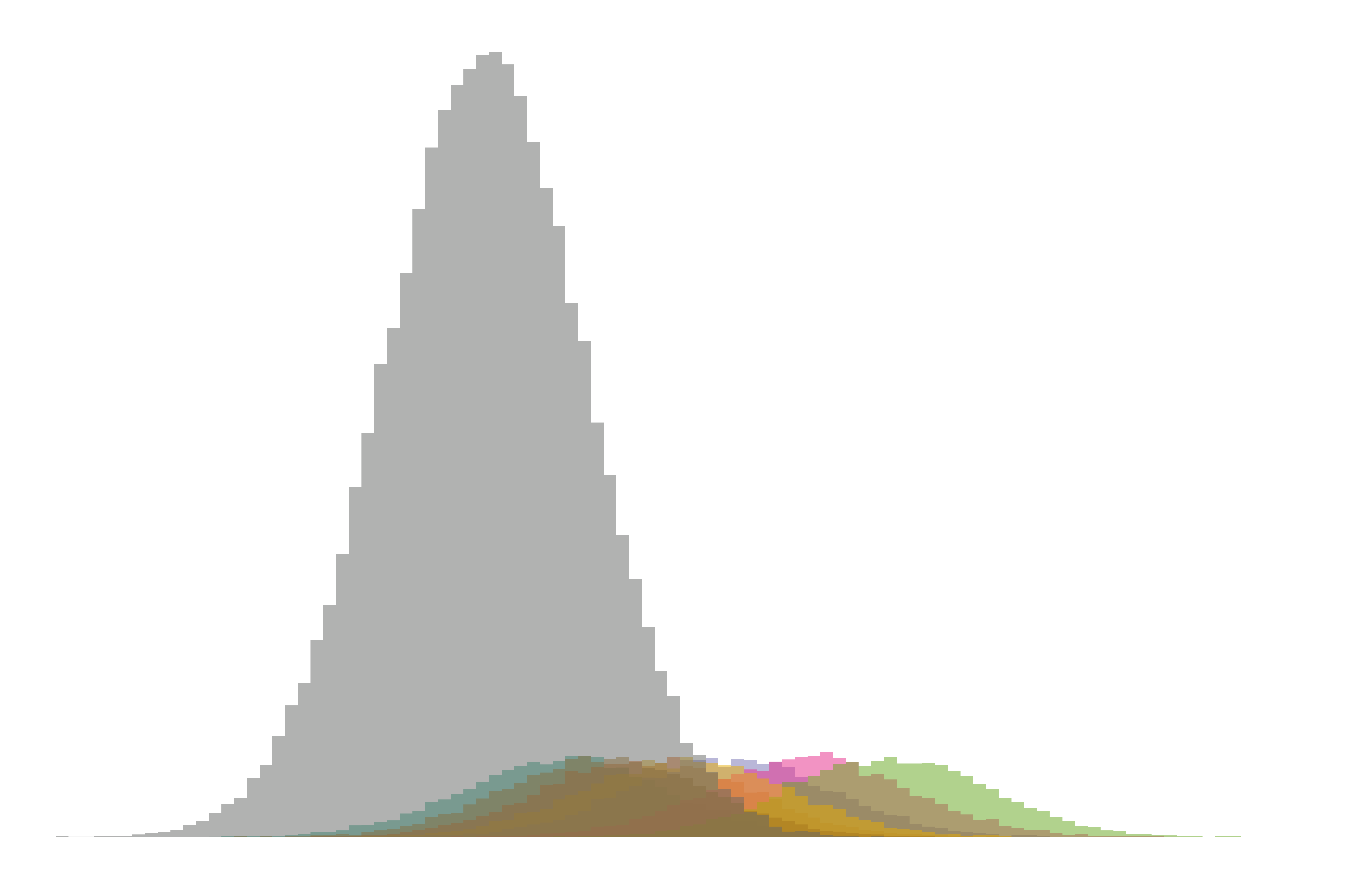 |
|---|
| Figure 2. Partitioned data from Figure 1. The skew in Figure 1 was created by overlapping Gaussian distributions, a major one (grey) and seven minor ones with higher means (colours). |
If it is decided that a transformation is appropriate, then it must be decided which to use. Again, information regarding this decision is ideally obtained from independent sources, such as published papers. It is reasonably common for biochemistry analytes to be right-skewed (tail on the right). Common transformations for right-skewed data are square root, cube root and logarithms. A more general transformation function, favoured by the CLSI1 and IFCC2, is the Box-Cox transformation:
BhattApp and HoffApp are both able to perform all these transformations. The apps allow the use of ‘automatic’ Box-Cox transformation, where the best fit for the uploaded data is found, or ‘manual’ Box-Cox transformation, where the lambda can be specified by the analyst, which is useful if the best lambda value is known from a literature source.
References
- Clinical and Laboratory Standards Institute. CLSI document EP28-A3c. Wayne, PA, USA: CLSI; 2010. Defining, Establishing, and Verifying Reference Intervals in the Clinical Laboratory; Approved Guideline – Third Edition.
- Jones GR, Haeckel R, Loh TP, et al. IFCC Committee on Reference Intervals and Decision Limits. Indirect methods for reference interval determination - review and recommendations. Clin Chem Lab Med 2018; 57: 20–9. PubMed
